
Вход на сайт
Facebook назначаю виновным (обновлено)
вт, 2023-02-14 00:22 — elia
Per aspera ad astra
"Правильный" перевод: мы сами создаем себе проблемы, а потом героически их преодолеваем
Этот блог никогда не имел коммерческой направленности. Пригодная для коммерциализации тема декодирования VIN автомобилей ушла на отдельный домен carinfo.kiev.ua. Здесь же осталось то, что мне интересно, но чисто для души. Мои наблюдения, какие-то мысли, наработки в мире IT. Посещаемость меня не волнует: коды аналитики встроены в страницы сайта, но я ее (аналитику) никогда не смотрю. В 2017 по требованию платежных систем я перевел carinfo.kiev.ua на защищенный протокол SSL. Этот же домен переводить не стал, так как здесь нет ничего тайного и/или связанного с охраной личной или банковской тайны. Поэтому тратить деньги на покупку SSL сертификата посчитал излишним.
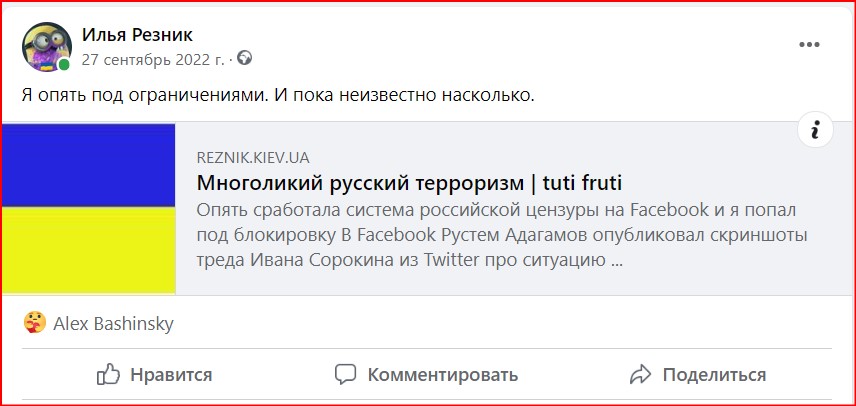
Последние несколько лет на Facebook появилась неприятная и непонятная для меня особенность: при "поделиться новостью" несмотря на возможность выбора изображения со страницы, в результате в публикации ленте Facebook упорно показывалось только лого сайта несмотря на любые мои ухищрения:
Но в последнее время, из-за роста количества публикаций в блоге, связанных с темой войны россии против Украины, эта особенность Facebook начала меня раздражать. Потыкался туда-сюда, спросил у Google - ответа нет. 11 января даже написал запрос в поддержку Facebook. И жизнь потекла дальше своим чередом...
5 февраля, обсуждая с единомышленниками один новый проект, снова уткнулся носом в то, что поисковики любят когда сайты защищены SSL сертификатом. И возникла у меня мысль, что проблема именно в протоколе - возможно Facebook отказывается принимать нормально ссылки на страницы без SSL. И решил таки закрыть свой блог сертификатом. За пару часов подобрал подходящего поставщика, заказал, оплатил, и установил сертификат на сервер. Сходил в свою ленту Facebook и подергал свои публикации из этого блога: если на странице публикации здесь заранее изменить ссылки на изображения с http на https, и два раза (?) отредактировать публикацию на Facebook, то публикация становится "нормальной", с интересными картинками. И даже через некоторое время обновится счетчик "нравится" на странице публикации здесь, который к большому сожалению обнуляется при переходе на другой протокол.
Можно так подергать счетчики на публикациях, которыми ты сам делился. Что делать с публикациями, которыми делились посетители сайта - у меня ответа нет. Скорее всего надо смириться с этой потерей.
Ок, что мы имеем: сайт переведен на SSL, но Facebook так же хочет, чтобы все ссылки на изображения на странице тоже были с использованием протокола https. Надо сделать пакетное обновление уже сделанных публикаций, так как в силу ряда причин ссылки на страницах почти всегда абсолютные, а не относительные (моя лень тут не на первых местах, но и далеко не последняя  ). Значит берем в руки case tools и делаем обновление базы сайта средствами SQL. Сначала для одной публикации:
). Значит берем в руки case tools и делаем обновление базы сайта средствами SQL. Сначала для одной публикации:
UPDATE node_revisions dnr SET dnr.teaser = REPLACE(dnr.teaser, 'http://reznik.kiev.ua', 'https://reznik.kiev.ua'), dnr.body = REPLACE(dnr.body, 'http://reznik.kiev.ua', 'https://reznik.kiev.ua') WHERE dnr.nid = 1695;
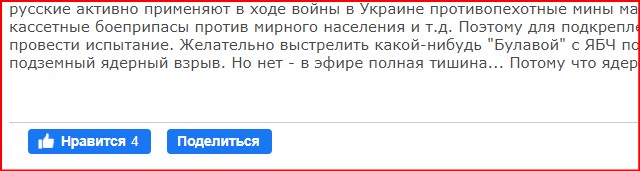
Двойное редактирование своей публикации в ленте Facebook - и результат налицо!
Ок, раз на тестовой публикации все прошло нормально, то теперь надо применить пакетную обработку для всех остальных. На всякий случай сначала делаю пакетное обновление тизеров публикаций:
UPDATE node_revisions dnr SET dnr.teaser = REPLACE(dnr.teaser, 'http://reznik.kiev.ua', 'https://reznik.kiev.ua');
Проверяю - все в порядке. Переходим к body (основному телу) публикаций. И 5 февраля в 16:42 (воскресенье!) следующей летит эта SQL команда:
UPDATE node_revisions dnr SET dnr.body = REPLACE(dnr.teaser, 'http://reznik.kiev.ua', 'https://reznik.kiev.ua') WHERE dnr.body LIKE '%http://reznik.kiev.ua%' ORDER BY dnr.nid DESC;
Проверяю результат и прихожу в шок: у публикаций исчезли body - вместо них записаны тизеры.  Не буду писать оправданий почему я пропустил эту дефективную команду, отмечу только что в ней не так: если в body публикации есть текст "http://reznik.kiev.ua", то в body пишется текст из teaser! Осознав произошедшее я пришел в ужас: под нож попали более тысячи публикаций! И отменить сделанное невозможно!
Не буду писать оправданий почему я пропустил эту дефективную команду, отмечу только что в ней не так: если в body публикации есть текст "http://reznik.kiev.ua", то в body пишется текст из teaser! Осознав произошедшее я пришел в ужас: под нож попали более тысячи публикаций! И отменить сделанное невозможно!
Мой сайт работает с базой данных в формате MyISAM. Во первых это опция по умолчанию при установке (а первые 8 лет сайт существовал на разных виртуальных хостингах, где InnoDB далеко не всегда поддерживался), во вторых этот формат занимает на 30% меньше места, чем "транзакционный" InnoDB. А при малой интенсивности записей в базу MyISAM (контент на сайт вношу только я и это несколько публикаций в день) еще и будет быстрее для чтения. Опережают его в скорости чтения сжатые (compressed) таблицы, которые можно использовать только для чтения. То есть сделать rollback транзакции не получится. Раньше у меня каждую ночь по крону снимались резервные дампы баз всех сайтов. Потом я разжился сервером репликации баз данных из-за carinfo.kiev.ua, и теперь уже на сервере репликации продолжали сниматься дампы с реплицированной базы данных (что позволяло основному сайту всегда быть онлайн). Но летом 2019 у меня были проблемы со свободным местом на сервере репликации, я арендовал более мощный сервер и... и сделав тестовые дампы, cron так и не запустил на нем.
Имея тестовый дамп базы сайта от лета 2019 года я восстановил более ранние публикации. Какое-то количество из них я правил после этого, но уже что есть, то есть. Осталось почти семьсот публикаций после 24.02.2022, резервных копий которых у меня под рукой нет. Их восстановление заняло 7 суток без пары часов. Это была не круглосуточная работа: есть основная работа, семейная жизнь и самый роковой фактор - регулярные отключения электроэнергии из-за обстрелов критической инфраструктуры Украины крылатыми ракетами кремлевскими террористами. Последний фактор оказался самым значительным: пока я вынужденно бездействовал из-за отсутствия электроэнергии и интернета, сайт на сервере в Западной Европе продолжал крутиться и все, в том числе и боты поисковых систем, видели мой позор. И это очень сильно деморализовало меня и вселяло панику. А паника приводит к ошибкам и лишним действиям... Как я выбирался из собственноручно созданной ямы:
- [ошибка] Первым делом я начал восстанавливать страницы с ежедневными сводками на основе данных из специальной БД под эти цели. Два дня я восстанавливал 345 страниц.
Позитив: все страницы сводок теперь в унифицированном последнем формате вместо десятка версий от полностью ручной работы в первые дни до шаблонного копировать-вставить с октября 2022 года.
Негатив: Потеряны комментарии и другие дополнения, которыми я особенно активно снабжал эти публикации в первые полгода войны. - По составленному списку оставшихся поврежденных публикаций пошел рыться в web.archive.org. Публикации проверял не последовательно, а выборочно, опираясь на свои представления значимости публикаций. Работа шла медленно: как только находил копию страницы в кеше, то бросался сразу ее полностью восстанавливать. Очень часто утыкался в отсутствие в архиве страниц, что привело к сильному расстройству и полной приостановке работ по восстановлению. А там и электроэнергию выключили с 21 часа на четыре часа.
- На следующий день этот же список публикаций начал проверять в кеше Google - что-то было, чего-то не было. Но не было и некоторых самых критичных (можно сказать "любимых") публикаций. Расстроился, опять выключили электроэнергию, ушел спать.
- На следующий день с самого утра продолжил копаться в Google, но мне стали попадаться уже обновленные после факапа от 5 февраля поврежденные страницы моего сайта! В середине дня очередное отключение электроэнергии на 4 часа, отчаяние...
- После возобновления подачи электроэнергии перешел от выборочного опроса кешей поисковых систем к методичной работе:
- Закрыл доступ к сайту поисковых роботов через изменения в robots.txt
- Создал временную таблицу, куда залил URL поврежденных страниц, добавил поля для сохранения дампов от Wayback machine, Google, Yahoo с типом данных longtext
- Создал скрипт для поиска копий страниц в Wayback machine через JSON API, который запускался по крону и принес мне почти 50 страниц моего сайта
- По полученным URL к кэшированным страницам вручную открыл их, скопировал исходный текст и записал в поля временной таблицы
- Попробовал создать и отладить скрипт для работы с API поисковой системой Google, но как только понял, что процесс растягивается минимум на несколько часов, а скорее всего на пару дней, то прекратил эту работу. Вместо этого начал брать подряд URL страниц, оставшихся после Wayback machine, и вставлять их просто в поисковую строку Google. Если страница появлялась в первом десятке результатов и имела кэшированную версию, то открывал эту версию, копировал исходный текст страницы, вставлял в свою временную таблицу
- Оставшиеся дыры в своей временной таблице закрывал с помощью аналогичного поиска в Yahoo. Этот поисковик использовал как запасной по одной причине: намного больше операций по удалению из полученной от него копии страницы встроенной цветовой маркировки слов из поиска. В отличие от Google, который из кэша выводит страницу в состоянии "как есть".
- Bing от Microsoft попробовал немного, но быстро забросил - он не любит мои сайты. Даже ходит на них крайне редко.
- По оставшимся без копии после предыдущих проверок страницам пошел уже более вдумчиво по поиску Google и Yahoo: делал поиски по запросам вида "site: reznik.kiev.ua "Заголовок страницы"" и затем "site: reznik.kiev.ua "Текст из тизера"". Результаты необходимо было уже просматривать неспешно: одну свою страницу нашел только на 8й стране результатов поиска в Google. В Yahoo нужную страницу найти на 2...3 странице выдачи - это почти норма. Надо смотреть не только на текст ссылки с результатом, но и на краткую аннотацию под ней: иногда нужный результат находился под заголовком со стартовой страницы сайта. Эту достаточно значимую для меня страницу именно таким путем я нашел далеко не с первой попытки, потому что по запросу URL или заголовка страницы Google возвращал мне кэшированную версию страницы, которую он снял через 40 минут после факапа. Но я ее нашел все-таки В кэше Google
- Оставшиеся после предыдущих этапов страницы (чуть меньше 20 страниц) собирал уже по сусекам: находил источники, откуда брался основной текст, и заполнял публикации. Правда уже без моих сопроводительных комментариев. Несколько публикаций смог восстановить с помощью своей ленты Facebook: из ленты Facebook брал текст из середины публикации (я часто при "поделиться" в ленте Facebook вставляю копию части текста публикации у себя на сайте) и по нему уже находил нужный мне кэш в поиске Google или Yahoo.
- Параллельно в качестве разрядки "лотами" вносил восстановленные тексты в публикации на моем сайте
В результате не смог восстановить только 4 публикации. Из почти семисот в начале! Не смог восстановить три незначительные публикации и Краткие итоги Декабря и всего 2022 года . С последней публикацией что-то непонятное: я конечно ее публиковал 2 января, но не нашел вообще никаких ее следов нигде, и на Facebook я ею тоже не делился. Заговоренной оказалась, прям. Надо как-то ее восстанавливать, точне писать с нуля... [Проблема решена - читайте дополнение внизу страницы] Так же потеряны две недописанные публикации, сравнимые по объему с этой, которую Вы сейчас читаете. Их точно нет больше нигде
Итак. Опираясь на опыт выше последовательность действий в ситуации, когда база публикаций сайта повреждена, резервной копии базы нет, и ее надо как можно быстрее и полнее восстановить:
- Закрыть доступ к сайту поисковых роботов через изменения в robots.txt И чем скорее, тем лучше! Закрывать весь сайт ("User-agent: * Disallow: /") - тогда кэш сайта будет заморожен и Вы сможете спокойно в нем искать свои страницы. Если закрывать отдельные страницы, то они скорее всего выпадут из индекса и будут удалены из кэша поисковиков.
- Составить перечень URL страниц сайта для восстановления. Занести их в отдельную таблицу.
- Создать скрипт для поиска копий страниц в Wayback machine через JSON API, который будет записывать ответы сервера в таблицу из 1го пункта. И пропустить его по cron (я последовательно запрашивал по 2 URL из своего списка за одну сессию, так как очень часто приходилось долго ждать ответа сервера)
- По страницам с неудачным результатом поиска в предыдущем пункте проверить их на наличие в кэше поисковых систем Google и Yahoo. Степень автоматизации этого процесса зависит от объема работы. Я это выполнял вручную: брал URL страницы из таблицы и вставлял его в окно поиска на странице google.com и yahoo.com. Удачные ответы занести в таблицу из 1го пункта.
- По оставшимся без копии после предыдущих проверок страницам уже более вдумчиво идти по поиску Google и Yahoo: делать поиски по запросам вида "site: mydomain.com "Заголовок страницы"" и затем "site: mydomain.com "Текст из тизера"".
- По оставшимся без копии после предыдущих проверок страницам сделать поиск в социальных сетях: Вы или кто-то другой могли поделиться полным текстом этой публикации.
- Внести найденные копии страниц в базу сайта. Этот пункт можно выполнять параллельно с предыдущими, но надо сохранять правильный баланс: как можно более скорая и полная добыча данных важнее их внесения в базу сайта.
- Открыть (восстановить в прежнем объеме) доступ к сайту поисковых роботов через изменения в robots.txt
- Через 1...2 дня зайти в консоль вебмастера хотя бы на одном из поисковиков и убедиться, что индексирование сайта восстановлено и функционирует в нормальном режиме.
- И самый главный пункт: обязательно наладить автоматическое создание резервных копий базы сайта! Желательно раз в сутки и чтобы были отдельные дампы за последние 7...14 дней!
Самый лучший вариант: создать сервер репликации базы данных (он должен быть не просто на другой "железке", а в другом датацентре!), на котором уже делать резервные дампы. Таким образом тяжелая процедура формирования дампов не будет влиять на работу сайта. Сервер репликации может спокойно приостановить свою основную работу, сделать дамп, а потом "н еторопясь" нагнать журнал репликации.
Если бы у меня была резервная копия базы данных, то полное восстановление публикаций заняло бы 2...3 часа максимум (вспомнить настройки подключения к серверу репликации, зайти, вспомнить расположение дампов, скачать дамп, разархивировать, развернуть на временном сервере, скопировать нужные таблицы и т.д.). Так что делайте регулярные резервные копии базы данных.
Добавление от 15.02.2023:
Статью Краткие итоги Декабря и всего 2022 года смог восстановить! Это удалось сделать с помощью программы ChromeCacheView, которая умеет доставать данные из кэша браузеров на разных самых распространенных платформах (кроме Firefox, для которого используется отдельная утилита MZCacheView от тех же авторов)!
Важно! Для восстановления данных из кэша браузера на компьютере, где возможно была ранее просмотрена искомая страница в полном варианте, ни в коем случае не открывайте страницу в самом браузере до попытки восстановления, ведь в таком случае кэш браузера обновится самой последней "побитой" версией страницы.
И это наверное единственный способ восстановить публикацию, которую Вы написали, но еще не публиковали для открытого доступа, и/или страницы с ограниченным доступом, которые поисковики не могут проиндексировать.
Re: Facebook назначаю виновным
Статью Краткие итоги Декабря и всего 2022 года смог восстановить! Это удалось сделать с помощью программы ChromeCacheView, которая умеет доставать данные из кэша браузеров на разных самых распространенных платформах (кроме Firefox, для которого используется отдельная утилита MZCacheView от тех же авторов)!
Это удалось сделать с помощью программы ChromeCacheView, которая умеет доставать данные из кэша браузеров на разных самых распространенных платформах (кроме Firefox, для которого используется отдельная утилита MZCacheView от тех же авторов)!
Важно! Для восстановления данных из кэша браузера на компьютере, где возможно была ранее просмотрена искомая страница в полном варианте, ни в коем случае не открывайте страницу в самом браузере до попытки восстановления, ведь в таком случае кэш браузера обновится самой последней "побитой" версией страницы.
Я полный текст этой страницы нашел в кэше браузера на рабочем компьютере, где я эту страницу почему-то открывал 3 февраля. И не важно почему я ее открывал с рабочего компьютера! Важно, что страница восстановлена!
Отправить новый комментарий